We're very excited to announce that Lisa Huff, our Chief Technology Analyst here at DataCenterStocks.com, will be teaching a short course at the 2011 OFC show on Copper vs. Fiber in the Data Center.
More detail on the course should be available shortly at http://www.ofcnfoec.org/Short_Courses/index.aspx.

Friday, July 30, 2010
Top-of-Rack Switching – Better or Worse for Your Data Center? (Part 2)
by Lisa Huff
Last week I gave you some reasons why a Top-of-Rack (ToR) switching architecture could be higher cost for your data center network. Today, I’d like to discuss the advantages of using a ToR switching topology.
1) CLOS network architecture – in order to support this, you most likely need to use a ToR switch. For those not familiar with the CLOS network, it is a multi-stage network whose main advantage is that it requires fewer cross-points to produce a non-blocking structure. It is difficult and can be more costly to implement a non-blocking network without CLOS.
2) Latency and throughput – while it may be counter-intuitive, there may be less latency in your network if you use a ToR switch architecture. The main reason really has little to do with the switch itself and more to do with the data rate of your network. 10-Gigabit Ethernet typically has about 1/5th the latency that Gigabit Ethernet does. It also obviously has the capability of 10 times the throughput – provided that your switches can support line-rate (their backplanes can handle 10 Gbps). So implementing 10GigE in your equipment access layer of your data center can seriously reduce the amount of time data takes to get from initiator to destination. This, of course, is more critical in some vertical markets than in others – like the financial sector where micro-seconds can make a difference of millions of dollars made or lost.
A comment on latency and throughput however – if this is so critical, why not use InfiniBand instead of Ethernet ToR switches? It seems to me that InfiniBand already has these issues solved without adding another switch layer to the network.
Last week I gave you some reasons why a Top-of-Rack (ToR) switching architecture could be higher cost for your data center network. Today, I’d like to discuss the advantages of using a ToR switching topology.
1) CLOS network architecture – in order to support this, you most likely need to use a ToR switch. For those not familiar with the CLOS network, it is a multi-stage network whose main advantage is that it requires fewer cross-points to produce a non-blocking structure. It is difficult and can be more costly to implement a non-blocking network without CLOS.
2) Latency and throughput – while it may be counter-intuitive, there may be less latency in your network if you use a ToR switch architecture. The main reason really has little to do with the switch itself and more to do with the data rate of your network. 10-Gigabit Ethernet typically has about 1/5th the latency that Gigabit Ethernet does. It also obviously has the capability of 10 times the throughput – provided that your switches can support line-rate (their backplanes can handle 10 Gbps). So implementing 10GigE in your equipment access layer of your data center can seriously reduce the amount of time data takes to get from initiator to destination. This, of course, is more critical in some vertical markets than in others – like the financial sector where micro-seconds can make a difference of millions of dollars made or lost.
A comment on latency and throughput however – if this is so critical, why not use InfiniBand instead of Ethernet ToR switches? It seems to me that InfiniBand already has these issues solved without adding another switch layer to the network.
Thursday, July 29, 2010
Equinix Revenue Per Cabinet Up 8% Y/Y in North America
Wall Street loved Equinix's (EQIX) earnings report, with the stock closing up 6.5% today, even though it came in at expected revenue and EBITDA levels, and the company only lifted EBITDA guidance by a fraction.
The company's year-over-year revenue growth, excluding Switch & Data, was 21%, down from 25% last quarter. In addition to expansion, this continued revenue growth was helped by monthly recurring revenues per cabinet climbing to $2,053 in North America, up 8% from $1,893 a year ago. Overall revenue growth per cabinet was held back by the Euro falling during the quarter, but this is an important element of what the company claims is a 30-40% 5 year IRR on its investment in the IBX centers.
The company has over $2 billion of debt, but with adjusted EBITDA margins in the low 40s, it is not facing any major liquidity issues. With a debt/equity ratio over 1, the company is essentially borrowing away to build capacity beyond what any competitor will ever likely reach, while keeping its cost of capital down. And with not only revenue growing, but revenue per cabinet increasing, it is hard to argue against this strategy. However, it will be interesting to see what happens with Telx, which does just 1/10th the revenue Equinix does now, but leases its facilities instead of buying them. As a result, it has a Revenue/PP&E ratio of 1.5, compared to .6 for Equinix. The trade-off is that Telx's EBITDA margins are about 20 points lower, but could improve once that provider grows. Either way, the limited space in key markets like Northern New Jersey and Northern Virginia is helping both providers right now.
The company's year-over-year revenue growth, excluding Switch & Data, was 21%, down from 25% last quarter. In addition to expansion, this continued revenue growth was helped by monthly recurring revenues per cabinet climbing to $2,053 in North America, up 8% from $1,893 a year ago. Overall revenue growth per cabinet was held back by the Euro falling during the quarter, but this is an important element of what the company claims is a 30-40% 5 year IRR on its investment in the IBX centers.
The company has over $2 billion of debt, but with adjusted EBITDA margins in the low 40s, it is not facing any major liquidity issues. With a debt/equity ratio over 1, the company is essentially borrowing away to build capacity beyond what any competitor will ever likely reach, while keeping its cost of capital down. And with not only revenue growing, but revenue per cabinet increasing, it is hard to argue against this strategy. However, it will be interesting to see what happens with Telx, which does just 1/10th the revenue Equinix does now, but leases its facilities instead of buying them. As a result, it has a Revenue/PP&E ratio of 1.5, compared to .6 for Equinix. The trade-off is that Telx's EBITDA margins are about 20 points lower, but could improve once that provider grows. Either way, the limited space in key markets like Northern New Jersey and Northern Virginia is helping both providers right now.
Akamai Selloff is Completely Unjustified
Akamai (AKAM) reported quarterly revenue yesterday of $245 million, up from $240 million last quarter, and $205 million for the last year.
The stock is getting hit hard, however, as some traders seem concerned about a slight EPS hit, some of which is from currency conversions, as well as rumors of heavy price competition against Level 3 (LVLT) and Limelight (LLNW).
I think this beating is completely unjustified. The stock has a P/E of 30 overall, which drops to around 25 when you factor out its $1.1 billion cash balance. Moreover, the analysts on the call yesterday were fretting about one or two points of gross margin. I've been doing financial plans for telecom service providers for over a decade, and not one has come close to a 70% gross margin on a GAAP basis, or the low 80s on a cash basis. Moreover, the difference in cash and GAAP gross margins shows what a poor job financial accounting does of revealing cost structure with depreciation and stock-based compensation thrown into the Cost of Goods Sold line. This is why I recommend modeling businesses like this using managerial accounting techniques. Contribution margin provides a lot more insight into future profitability than GAAP gross margin for a company like this.
In addition to Wall Street's sudden concern about valuation, the strangest reaction I've seen to the earnings call is Citi's comment about competitors and pricing. CDNs are like semiconductors, the prices are almost always declining, but the margins remain high throughout because the underlying costs are declining at the same rate. This is Microeconomics 101, prices for CDN services will keep dropping because the marginal costs of delivering them keep dropping. The servers and network connections in Akamai's network aren't getting more expensive. Moreover, Akamai's got the lowest cost per bit because its got the largest CDN network. Its operating margins have been holding around 25%, while competitor Limelight has been holding around minus 15%. Competitors therefore have to go Akamai's cost per bit, so guess who gets hurt more in a price war. Moreover, it takes a lot of specialized, expensive knowledge to sell CDN services, which is one reason why telcos have struggled with it, because they could easily handle the capital requirements. At the end of last year, Akamai had 820 people in sales and support. Even large telcos don't have this level of CDN expertise, which is why Verizon and Telefonica resell Akamai's service rather than trying to compete against it.
There might be temporary spikes up and down, but this company has accumulated over $1 billion in cash while prices for its service have kept dropping. If Intel (INTC) can hold a $120 billion market cap for a business with no pricing power but the lowest marginal cost per unit of production, Akamai's $1.1 billion of cash and quarter billion of operating income are certainly enough to justify a $7.5 billion market cap.
The stock is getting hit hard, however, as some traders seem concerned about a slight EPS hit, some of which is from currency conversions, as well as rumors of heavy price competition against Level 3 (LVLT) and Limelight (LLNW).
I think this beating is completely unjustified. The stock has a P/E of 30 overall, which drops to around 25 when you factor out its $1.1 billion cash balance. Moreover, the analysts on the call yesterday were fretting about one or two points of gross margin. I've been doing financial plans for telecom service providers for over a decade, and not one has come close to a 70% gross margin on a GAAP basis, or the low 80s on a cash basis. Moreover, the difference in cash and GAAP gross margins shows what a poor job financial accounting does of revealing cost structure with depreciation and stock-based compensation thrown into the Cost of Goods Sold line. This is why I recommend modeling businesses like this using managerial accounting techniques. Contribution margin provides a lot more insight into future profitability than GAAP gross margin for a company like this.
In addition to Wall Street's sudden concern about valuation, the strangest reaction I've seen to the earnings call is Citi's comment about competitors and pricing. CDNs are like semiconductors, the prices are almost always declining, but the margins remain high throughout because the underlying costs are declining at the same rate. This is Microeconomics 101, prices for CDN services will keep dropping because the marginal costs of delivering them keep dropping. The servers and network connections in Akamai's network aren't getting more expensive. Moreover, Akamai's got the lowest cost per bit because its got the largest CDN network. Its operating margins have been holding around 25%, while competitor Limelight has been holding around minus 15%. Competitors therefore have to go Akamai's cost per bit, so guess who gets hurt more in a price war. Moreover, it takes a lot of specialized, expensive knowledge to sell CDN services, which is one reason why telcos have struggled with it, because they could easily handle the capital requirements. At the end of last year, Akamai had 820 people in sales and support. Even large telcos don't have this level of CDN expertise, which is why Verizon and Telefonica resell Akamai's service rather than trying to compete against it.
There might be temporary spikes up and down, but this company has accumulated over $1 billion in cash while prices for its service have kept dropping. If Intel (INTC) can hold a $120 billion market cap for a business with no pricing power but the lowest marginal cost per unit of production, Akamai's $1.1 billion of cash and quarter billion of operating income are certainly enough to justify a $7.5 billion market cap.
I/O Virtualization vs. Fibre Channel over Ethernet
by David Gross
Somehow vendors always want to converge networks just when IT managers are finding new applications for existing technologies. This results in new products banging against unintended uses for established technologies. In turn, vendors create new “convergence” tools to pull everything back together, which then bump up against the IT managers' new applications, and the cycle repeats. This has been a pattern in data networking for at least the last 15 years, where vendor visions of one big happy network have kept colliding with the operating reality of a network that keeps diverging and splitting into new forms and functions. If reality had played out like vendor PowerPoints of years past, we'd all have iSCSI SANs incorporated into IPv6 based-LANs, and Fibre Channel and InfiniBand would be heading to the history books with FDDI and ATM.
Like previous attempts to force networks together, current attempts to do so require expensive hardware. As I pointed out a couple of weeks ago, Fibre Channel over Ethernet looks good when modeled in a PowerPoint network diagram, but not so great when modeled in an Excel cost analysis, with its CNAs still topping $1,500, or about 3x the cost of 10 Gigabit Ethernet server NICs. But this is not the only way to glue disparate networks together, I/O Virtualization can achieve the same thing by using an InfiniBand director to capture all the Ethernet and Fibre Channel traffic.
I/O Virtualization can offer a lower cost/bit at the network level than FCoE, because it can run at up to 20 Gbps. However, I/O Virtualization directors are more expensive than standard InfiniBand directors. Xsigo's VP780, sold through Dell, sells for around $1,000 per DDR port, while a Voltaire (VOLT) 4036E Grid Director costs about $350 per faster QDR port. But this could change quickly once the technology matures.
One major difference in the configuration between standard InfiniBand and I/O Virtualization is that a typical InfiniBand director, such as a Voltaire 4036E, bridges to Ethernet in the switch, while Xsigo consolidates the I/O back at the server NIC. The cost of the additional HCA in the standard InfiniBand configuration is about $300 per port at DDR rates and $600 per port at QDR rates. A 10 Gigabit Ethernet server NIC costs around $500 today, and this price is dropping, although there is some variability based on which 10 Gigabit port type is chosen – CX4, 10GBASE-T, 10 GBASE-SR, etc. Either way, while it saves space over multiple adapters, the I/O Virtualization card still needs to cost under $800 at 10 Gigabit to match the costs of buying separate InfiniBand and Ethernet cards. Moreover, the business case depends heavily on which variant of 10 Gigabit Ethernet is in place. A server with mutliple 10GBASE-SR ports is going to offer a lot more opportunity for a lower cost alternative than one with multiple 10GBASE-CX4 ports.
I/O Virtualization can eliminate the practice of one NIC or HBA per virtual machine in a virtualized environment. However, the two major buyers of InfiniBand products, supercomputing centers and financial traders, have done little with server virtualization, and therefore don't stand to benefit greatly from I/O Virtualization.
While there is growing interest in I/O Virtualization, it runs the risk of bumping into some of the cost challenges that have slowed Fibre Channel over Ethernet. Moreover, industries like supercomputing and financial trading are sticking mostly to diverged hardware to obtain the best price/performance. Nonetheless, I/O Virtualization could offer an opportunity to bridge networks at the NIC level instead of at the switch, while still getting some of the price/performance benefits of InfiniBand.
Somehow vendors always want to converge networks just when IT managers are finding new applications for existing technologies. This results in new products banging against unintended uses for established technologies. In turn, vendors create new “convergence” tools to pull everything back together, which then bump up against the IT managers' new applications, and the cycle repeats. This has been a pattern in data networking for at least the last 15 years, where vendor visions of one big happy network have kept colliding with the operating reality of a network that keeps diverging and splitting into new forms and functions. If reality had played out like vendor PowerPoints of years past, we'd all have iSCSI SANs incorporated into IPv6 based-LANs, and Fibre Channel and InfiniBand would be heading to the history books with FDDI and ATM.
Like previous attempts to force networks together, current attempts to do so require expensive hardware. As I pointed out a couple of weeks ago, Fibre Channel over Ethernet looks good when modeled in a PowerPoint network diagram, but not so great when modeled in an Excel cost analysis, with its CNAs still topping $1,500, or about 3x the cost of 10 Gigabit Ethernet server NICs. But this is not the only way to glue disparate networks together, I/O Virtualization can achieve the same thing by using an InfiniBand director to capture all the Ethernet and Fibre Channel traffic.
I/O Virtualization can offer a lower cost/bit at the network level than FCoE, because it can run at up to 20 Gbps. However, I/O Virtualization directors are more expensive than standard InfiniBand directors. Xsigo's VP780, sold through Dell, sells for around $1,000 per DDR port, while a Voltaire (VOLT) 4036E Grid Director costs about $350 per faster QDR port. But this could change quickly once the technology matures.
One major difference in the configuration between standard InfiniBand and I/O Virtualization is that a typical InfiniBand director, such as a Voltaire 4036E, bridges to Ethernet in the switch, while Xsigo consolidates the I/O back at the server NIC. The cost of the additional HCA in the standard InfiniBand configuration is about $300 per port at DDR rates and $600 per port at QDR rates. A 10 Gigabit Ethernet server NIC costs around $500 today, and this price is dropping, although there is some variability based on which 10 Gigabit port type is chosen – CX4, 10GBASE-T, 10 GBASE-SR, etc. Either way, while it saves space over multiple adapters, the I/O Virtualization card still needs to cost under $800 at 10 Gigabit to match the costs of buying separate InfiniBand and Ethernet cards. Moreover, the business case depends heavily on which variant of 10 Gigabit Ethernet is in place. A server with mutliple 10GBASE-SR ports is going to offer a lot more opportunity for a lower cost alternative than one with multiple 10GBASE-CX4 ports.
I/O Virtualization can eliminate the practice of one NIC or HBA per virtual machine in a virtualized environment. However, the two major buyers of InfiniBand products, supercomputing centers and financial traders, have done little with server virtualization, and therefore don't stand to benefit greatly from I/O Virtualization.
While there is growing interest in I/O Virtualization, it runs the risk of bumping into some of the cost challenges that have slowed Fibre Channel over Ethernet. Moreover, industries like supercomputing and financial trading are sticking mostly to diverged hardware to obtain the best price/performance. Nonetheless, I/O Virtualization could offer an opportunity to bridge networks at the NIC level instead of at the switch, while still getting some of the price/performance benefits of InfiniBand.
Wednesday, July 28, 2010
Voltaire Revenue Up 7% Sequentially, 54% Year-over-Year
InfiniBand switch maker Voltaire (VOLT) reported quarterly revenues this morning of $16.6 million, a 54% increase from its 2nd quarter of 2009, and it reaffirmed guidance of $67-70 million for 2010 revenue, reassuring investors who were spooked by Mellanox's (MLNX) downward guidance revision last week.
While it is making every effort to play nice with Ethernet, the company was one of the first to release QDR InfiniBand director and switch ports, which has helped its revenue reverse course off a downward trend it hit during 2008 and 2009.
While it is making every effort to play nice with Ethernet, the company was one of the first to release QDR InfiniBand director and switch ports, which has helped its revenue reverse course off a downward trend it hit during 2008 and 2009.
F5's Market Cap Surpasses Alcatel-Lucent's
The price spike after F5's (FFIV) earnings call last week pushed its market cap over $6.5 billion, surpassing industry stalwart Alcatel-Lucent (ALU), which was at $6.2 billion after yesterday's close. This is an absolutely remarkable development for the networking industry, and shows how important it is to stay focused on industry sub-segments where you're either #1 or #2.
If you think of some of the highest revenue product categories in networking, from core routing to Ethernet switching to 4G wireless, Alcatel-Lucent is in every one of them, while F5 is none of them. So why is its market cap higher?
F5's valuation is a little rich, but certainly not wildly out of control in a 1999 sort of way. It has $780 million of cash and investments, no long-term debt, $40.5 million in net income last quarter, and a $6.9 billion market cap as of yesterday's close. Net of cash this gives the stock a P/E of 38 on annualized earnings, which is lower than its 46% top line growth rate over the last 12 months, and its nearly 90% bottom line growth for the last year.
Excessive optimism is not really the cause of F5 leaping past Alcatel-Lucent, but tremendous focus is. The company does not have an offering in any of the major networking categories, but it is a leader in a growing niche. Alcatel-Lucent, on the other hand, participates in just about every major segment, but leads very few. And its financial reflect this. Its gross margins have been hanging around the low 30s, while F5's have been pushing 80%. While many of the telecom products Alcatel-Lucent offers sell for lower gross margins due to high raw materials costs, Infinera (INFN), which is focused entirely on the low gross margin optical sector, is now posting higher gross margins than Alcatel-Lucent.
Still Recovering from McGinn-Russo
The current challenges at Alcatel-Lucent really have little to do with current management, and in fairness to the new executive team, they have been very focused on reducing overheads and trimming expenses in spite of stereotypes about bloated French bureaucracies. The company's SG&A/Revenue ratio is down to 21%, lower than many of the smaller vendors. Moreover, just 12% of the company's workforce is in France.
Alcatel-Lucent's challenge is the incredibly diverse set of products it must manage, which in part reflects the wild acquisition and over-diversification of the McGinn-Russo era at Lucent, as well as the old school approach of being a supplier who does everything for its telecom customers. This is one reason why its gross margins are low, it has long inventory cycles and must support production and development across a wide range of data, optical, and wireless products. F5, on the other hand, has never tried to have a high "share of wallet", because much of its customers' equipment spending goes to routers and Ethernet switches, neither of which are in its product catalog.
Ten years ago, it was said that startups had no shot at competing against large suppliers like Lucent, Nortel, and Alcatel at major carriers. While this was factually true, it concealed the fact that there was little economic value to being a diversified telco supplier. Even Cisco (CSCO) struggled to break into the carrier market, and scaled back its optical ambitions when its killed its optical switch acquired through Monterrey, and it never even tried to get into 3G or 4G wireless.
Alcatel-Lucent still leads some product categories, notably DSL and Fiber-to-the-Home. Nonetheless, it still needs to trim down its offerings if it wants its market cap to catch up with those vendors generating higher gross margins by offering fewer products.
If you think of some of the highest revenue product categories in networking, from core routing to Ethernet switching to 4G wireless, Alcatel-Lucent is in every one of them, while F5 is none of them. So why is its market cap higher?
F5's valuation is a little rich, but certainly not wildly out of control in a 1999 sort of way. It has $780 million of cash and investments, no long-term debt, $40.5 million in net income last quarter, and a $6.9 billion market cap as of yesterday's close. Net of cash this gives the stock a P/E of 38 on annualized earnings, which is lower than its 46% top line growth rate over the last 12 months, and its nearly 90% bottom line growth for the last year.
Excessive optimism is not really the cause of F5 leaping past Alcatel-Lucent, but tremendous focus is. The company does not have an offering in any of the major networking categories, but it is a leader in a growing niche. Alcatel-Lucent, on the other hand, participates in just about every major segment, but leads very few. And its financial reflect this. Its gross margins have been hanging around the low 30s, while F5's have been pushing 80%. While many of the telecom products Alcatel-Lucent offers sell for lower gross margins due to high raw materials costs, Infinera (INFN), which is focused entirely on the low gross margin optical sector, is now posting higher gross margins than Alcatel-Lucent.
Still Recovering from McGinn-Russo
The current challenges at Alcatel-Lucent really have little to do with current management, and in fairness to the new executive team, they have been very focused on reducing overheads and trimming expenses in spite of stereotypes about bloated French bureaucracies. The company's SG&A/Revenue ratio is down to 21%, lower than many of the smaller vendors. Moreover, just 12% of the company's workforce is in France.
Alcatel-Lucent's challenge is the incredibly diverse set of products it must manage, which in part reflects the wild acquisition and over-diversification of the McGinn-Russo era at Lucent, as well as the old school approach of being a supplier who does everything for its telecom customers. This is one reason why its gross margins are low, it has long inventory cycles and must support production and development across a wide range of data, optical, and wireless products. F5, on the other hand, has never tried to have a high "share of wallet", because much of its customers' equipment spending goes to routers and Ethernet switches, neither of which are in its product catalog.
Ten years ago, it was said that startups had no shot at competing against large suppliers like Lucent, Nortel, and Alcatel at major carriers. While this was factually true, it concealed the fact that there was little economic value to being a diversified telco supplier. Even Cisco (CSCO) struggled to break into the carrier market, and scaled back its optical ambitions when its killed its optical switch acquired through Monterrey, and it never even tried to get into 3G or 4G wireless.
Alcatel-Lucent still leads some product categories, notably DSL and Fiber-to-the-Home. Nonetheless, it still needs to trim down its offerings if it wants its market cap to catch up with those vendors generating higher gross margins by offering fewer products.
Tuesday, July 27, 2010
Cost Effective 10G Data Center Networks
by Lisa Huff
For networks running Gigabit Ethernet, it’s a no-brainer to use Category 5e or 6 cabling with low-cost copper switches for less than 100m connections because they are very reliable and cost about 40-percent less per port than short-wavelength optical ones. But for 10G, there are other factors to consider.
While 10GBASE-T ports are now supposedly available on switches (at least the top Ethernet switch vendors, Brocade, Cisco and Extreme Networks say they have them), is it really more cost effective to use these instead of 10GBASE-SR, 10GBASE-CX4 or 10GBASE-CR (SFP+ direct attach copper)? Well, again, it depends on what your network looks like and how well your data center electrical power and cooling structures are designed.
First, 10GBASE-CX4 is really a legacy product and is only available on a limited number of switches so you may want to rule this out right away. If you’re looking for higher density, but you can’t support too many higher power devices, I would opt for 10GBASE-SR because it has the lowest power consumption – usually less than 1W/port. And also, the useful life of LOMF is longer; it’s smaller so won’t take up as much space or block cooling airflow if installed under a raised floor.
If you don’t have a power or density problem and can make do with just a few 10G ports for a short distance, you may choose to use 10GBASE-CR (about $615/port). But, if you don’t have a power or density issue and you need to go longer than about 10m, you’ll still need to use 10GBASE-SR and if you need a reach of more than 300m you’ll need to either install OM4 cable (which will get you up to 600m in some cases) to use with your SR devices; or look at 10GBASE-LR modules ($2500/port) that will cost you about twice as much as the SR transceivers (about $1300/port). If your reach needs to be less than 100m and you can afford higher power, but you need the density, 10GBASE-T (<$500/port) may be your solution. If you have a mix of these requirements, you may want to make sure you opt for an SFP-based switch so you can mix long and short reaches and copper and fiber modules/cables for maximum flexibility.
So what’s the bottom line? Do an assessment of your needs in your data center (and the rest of your network for that matter) and plan them out in order to maximize the cost effectiveness of your 10G networks. One more thing – if you can wait a few months, you may want to consider delaying implementation of 10G until later this year when most of the 10GBASE-T chip manufacturers promise to have less than 2.5W devices commercially available, which will drastically reduce (about half) its per port power consumption.
For networks running Gigabit Ethernet, it’s a no-brainer to use Category 5e or 6 cabling with low-cost copper switches for less than 100m connections because they are very reliable and cost about 40-percent less per port than short-wavelength optical ones. But for 10G, there are other factors to consider.
While 10GBASE-T ports are now supposedly available on switches (at least the top Ethernet switch vendors, Brocade, Cisco and Extreme Networks say they have them), is it really more cost effective to use these instead of 10GBASE-SR, 10GBASE-CX4 or 10GBASE-CR (SFP+ direct attach copper)? Well, again, it depends on what your network looks like and how well your data center electrical power and cooling structures are designed.
First, 10GBASE-CX4 is really a legacy product and is only available on a limited number of switches so you may want to rule this out right away. If you’re looking for higher density, but you can’t support too many higher power devices, I would opt for 10GBASE-SR because it has the lowest power consumption – usually less than 1W/port. And also, the useful life of LOMF is longer; it’s smaller so won’t take up as much space or block cooling airflow if installed under a raised floor.
If you don’t have a power or density problem and can make do with just a few 10G ports for a short distance, you may choose to use 10GBASE-CR (about $615/port). But, if you don’t have a power or density issue and you need to go longer than about 10m, you’ll still need to use 10GBASE-SR and if you need a reach of more than 300m you’ll need to either install OM4 cable (which will get you up to 600m in some cases) to use with your SR devices; or look at 10GBASE-LR modules ($2500/port) that will cost you about twice as much as the SR transceivers (about $1300/port). If your reach needs to be less than 100m and you can afford higher power, but you need the density, 10GBASE-T (<$500/port) may be your solution. If you have a mix of these requirements, you may want to make sure you opt for an SFP-based switch so you can mix long and short reaches and copper and fiber modules/cables for maximum flexibility.
So what’s the bottom line? Do an assessment of your needs in your data center (and the rest of your network for that matter) and plan them out in order to maximize the cost effectiveness of your 10G networks. One more thing – if you can wait a few months, you may want to consider delaying implementation of 10G until later this year when most of the 10GBASE-T chip manufacturers promise to have less than 2.5W devices commercially available, which will drastically reduce (about half) its per port power consumption.
Monday, July 26, 2010
Savvis Revenue Up 1% year-over-year, raises EBITDA guidance
by David Gross
This morning, Savvis (SVVS) reported revenue of $221 million for the quarter, and raised its annual EBITDA guidance from $210-$225 million, to $220-$240 million.
Operating cash flow was $32 million, free cash -$19 million. The company has over $700 million of debt, some of which came from financing its recent acquisiton of Fusepoint.
Managed services are slowly catching up to colocation, with quarterly revenue climbing to $73 milion from $67 million in the year ago quarter, while colo has held steady at $84 million.
All in all, no big surprises.
This morning, Savvis (SVVS) reported revenue of $221 million for the quarter, and raised its annual EBITDA guidance from $210-$225 million, to $220-$240 million.
Operating cash flow was $32 million, free cash -$19 million. The company has over $700 million of debt, some of which came from financing its recent acquisiton of Fusepoint.
Managed services are slowly catching up to colocation, with quarterly revenue climbing to $73 milion from $67 million in the year ago quarter, while colo has held steady at $84 million.
All in all, no big surprises.
SFP+ Marks a Shift in Data Center Cabling
by Lisa Huff
With the advent of top-or-rack (ToR) switching and SFP+ direct attach copper cables, more data centers are able to quickly implement cost-effective 10G and beyond connections. ToR designs are currently one of two configurations:
1. GigE Category cabling (CAT5e, 6, or 6A) connection to each server with a 10G SFP+ or XFP uplink to either an EoR switch or back to a switch in the main distribution area (MDA)
2. SFP direct attach cabling connection to each server with a 10G SFP+ or XFP uplink to either an EoR switch or back to a switch in the MDA
Either way, SFP and SFP+ modules and cable assemblies are starting to see huge inroads where Category cabling used to be the norm. Consequently, structured cabling companies have taken their shot at offering the copper variants of these devices. Panduit was one of the first that offered an SFP direct-attach cable for the data center, but Siemon quickly followed suit and surpassed Panduit by offering both the copper and optical versions of the assemblies as well as the parallel optics QSFP+ AOC. Others rumored of working on entering into this market are Belden (BDC) and CommScope (CTV). This really marks a shift in philosophy for these companies who traditionally have stayed away from what they considered “interconnect” products. There are a couple of notable exceptions in Tyco Electronics and Molex that have both types of products, however.
So what makes these companies believe they can compete with the likes of Amphenol Interconnect (APH), Molex (MOLX) and Tyco Electronics (TEL)? Well, it might not be the fact that they think they can compete, but that they see some erosion of their patch cord businesses and view this as the only way to make sure the “interconnect” companies don’t get into certain customers. So, protecting their customer base by offering products they won’t necessarily make any money on – because, after all, many of them are actually private-labeled from the very companies they are trying to oust. Smart or risky? Smart, I think, because it seems to me that the future of the data center will be in short-reach copper and mid-range fiber in the form of laser-optimized multi-mode fiber (LOMF).
With the advent of top-or-rack (ToR) switching and SFP+ direct attach copper cables, more data centers are able to quickly implement cost-effective 10G and beyond connections. ToR designs are currently one of two configurations:
1. GigE Category cabling (CAT5e, 6, or 6A) connection to each server with a 10G SFP+ or XFP uplink to either an EoR switch or back to a switch in the main distribution area (MDA)
2. SFP direct attach cabling connection to each server with a 10G SFP+ or XFP uplink to either an EoR switch or back to a switch in the MDA
Either way, SFP and SFP+ modules and cable assemblies are starting to see huge inroads where Category cabling used to be the norm. Consequently, structured cabling companies have taken their shot at offering the copper variants of these devices. Panduit was one of the first that offered an SFP direct-attach cable for the data center, but Siemon quickly followed suit and surpassed Panduit by offering both the copper and optical versions of the assemblies as well as the parallel optics QSFP+ AOC. Others rumored of working on entering into this market are Belden (BDC) and CommScope (CTV). This really marks a shift in philosophy for these companies who traditionally have stayed away from what they considered “interconnect” products. There are a couple of notable exceptions in Tyco Electronics and Molex that have both types of products, however.
So what makes these companies believe they can compete with the likes of Amphenol Interconnect (APH), Molex (MOLX) and Tyco Electronics (TEL)? Well, it might not be the fact that they think they can compete, but that they see some erosion of their patch cord businesses and view this as the only way to make sure the “interconnect” companies don’t get into certain customers. So, protecting their customer base by offering products they won’t necessarily make any money on – because, after all, many of them are actually private-labeled from the very companies they are trying to oust. Smart or risky? Smart, I think, because it seems to me that the future of the data center will be in short-reach copper and mid-range fiber in the form of laser-optimized multi-mode fiber (LOMF).
Saturday, July 24, 2010
DLR Revenue in Line, FFO Comes Up Short
by David Gross
We'll have more on this, but the Digital Realty (DLR) call was slightly disappointing, with FFO coming in at 76 cents, compared to estimates of 83 cents. The REIT also cut FFO guidance for the year from $3.47 to a range of $3.24 to $3.32.
Revenue was up 27% year-over-year to $197 million.
We'll have more on this, but the Digital Realty (DLR) call was slightly disappointing, with FFO coming in at 76 cents, compared to estimates of 83 cents. The REIT also cut FFO guidance for the year from $3.47 to a range of $3.24 to $3.32.
Revenue was up 27% year-over-year to $197 million.
Friday, July 23, 2010
Does Mellanox Know How it Will Grow?
by David Gross
This week, Mellanox (MLNX) joined the list of data center hardware suppliers reporting double digit year-over-year revenue growth. Its top line grew 58% annually to $40 million this past quarter. However, unlike F5 Networks (FFIV) and EMC (EMC), which both guided up for their next reporting periods, Mellanox announced that it expected revenue to decline about 7% sequentially in the third quarter. While it claimed things should turn around in the 4th quarter, the stock was down 25% soon after the announcement.
The company claims that the reason for the temporary decline is a product shift to silicon and away from boards and host channel adapters. This represents a sharp reversal of the trend it saw for much of 2009, when adapter revenue grew while silicon revenue dropped. Given the timing of its 40/100 Gigabit and LAN-on-Motherboard product cycles, this trend could keep going back and forth in the future, which has a big impact on revenue because individual adapters sell for roughly ten times the price of individual semiconductors.
While investors reacted swiftly to the revenue announcement, a bigger concern is not the shifting revenue among product components, but the company's apparent lack of faith in the InfiniBand market is dominates. InfiniBand is a growing, high-end, niche technology. Among the world's 500 largest supercomputers, 42% use InfiniBand as their interconnect between server nodes. Two years ago, only 24% did, according to Top500.org. But InfiniBand's success in supercomputing has yet to translate into major wins in traditional data centers, where it runs into the mass of existing Ethernet switches.
The company's response, developed in conjunction with the InfiniBand Trade Association it is heavily involved with, has been to develop RDMA over Converged Ethernet, or RoCE, pronounced liked the character Sylvester Stallone played in the 70s and 80s. In many respects, RoCE is InfiniBand-over-Ethernet, it uses InfiniBand networking technologies, but slides them into Ethernet frames. Traditionally, pricing for one link technology over another has not been competitive, because low volume multi-protocol boards require more silicon and design work than single protocol equivalents. This has been seen in the more widely promoted Fibre Channel-over-Ethernet, where Converged Network Adapters based on that technology are still selling for about three times the price of standard 10 Gigabit Ethernet server NICs.
By investing in RoCE, Mellanox is basically saying InfiniBand will not be able to stimulate demand on its own in the data center, even though it offers remarkable price/performance in supercomputing clusters. Moreover, there is still plenty of opportunity for InfiniBand to have an impact as IT mangers begin to look at 40 Gigabit alternatives. But just as the company cannot seem to figure out if growth will come for adapter cards or silicon, its now going against its push for RoCE by touting a Google engineering presentation that highlighted the benefits of running pure InfiniBand in a data center network.
Mellanox has long been a high margin company with a dominant position in a niche technology, and its strong balance sheet reflects this heritage. And the stock's recent pummeling has sent the company's valuation down to just 2.5 times cash. But by sending out so many conflicting messages about chips vs. cards and InfiniBand vs. Ethernet, the question is not whether investors have confidence in the company's growth plans, but whether management does.
This week, Mellanox (MLNX) joined the list of data center hardware suppliers reporting double digit year-over-year revenue growth. Its top line grew 58% annually to $40 million this past quarter. However, unlike F5 Networks (FFIV) and EMC (EMC), which both guided up for their next reporting periods, Mellanox announced that it expected revenue to decline about 7% sequentially in the third quarter. While it claimed things should turn around in the 4th quarter, the stock was down 25% soon after the announcement.
The company claims that the reason for the temporary decline is a product shift to silicon and away from boards and host channel adapters. This represents a sharp reversal of the trend it saw for much of 2009, when adapter revenue grew while silicon revenue dropped. Given the timing of its 40/100 Gigabit and LAN-on-Motherboard product cycles, this trend could keep going back and forth in the future, which has a big impact on revenue because individual adapters sell for roughly ten times the price of individual semiconductors.
While investors reacted swiftly to the revenue announcement, a bigger concern is not the shifting revenue among product components, but the company's apparent lack of faith in the InfiniBand market is dominates. InfiniBand is a growing, high-end, niche technology. Among the world's 500 largest supercomputers, 42% use InfiniBand as their interconnect between server nodes. Two years ago, only 24% did, according to Top500.org. But InfiniBand's success in supercomputing has yet to translate into major wins in traditional data centers, where it runs into the mass of existing Ethernet switches.
The company's response, developed in conjunction with the InfiniBand Trade Association it is heavily involved with, has been to develop RDMA over Converged Ethernet, or RoCE, pronounced liked the character Sylvester Stallone played in the 70s and 80s. In many respects, RoCE is InfiniBand-over-Ethernet, it uses InfiniBand networking technologies, but slides them into Ethernet frames. Traditionally, pricing for one link technology over another has not been competitive, because low volume multi-protocol boards require more silicon and design work than single protocol equivalents. This has been seen in the more widely promoted Fibre Channel-over-Ethernet, where Converged Network Adapters based on that technology are still selling for about three times the price of standard 10 Gigabit Ethernet server NICs.
By investing in RoCE, Mellanox is basically saying InfiniBand will not be able to stimulate demand on its own in the data center, even though it offers remarkable price/performance in supercomputing clusters. Moreover, there is still plenty of opportunity for InfiniBand to have an impact as IT mangers begin to look at 40 Gigabit alternatives. But just as the company cannot seem to figure out if growth will come for adapter cards or silicon, its now going against its push for RoCE by touting a Google engineering presentation that highlighted the benefits of running pure InfiniBand in a data center network.
Mellanox has long been a high margin company with a dominant position in a niche technology, and its strong balance sheet reflects this heritage. And the stock's recent pummeling has sent the company's valuation down to just 2.5 times cash. But by sending out so many conflicting messages about chips vs. cards and InfiniBand vs. Ethernet, the question is not whether investors have confidence in the company's growth plans, but whether management does.
Thursday, July 22, 2010
QLogic Revenue Up 16% Year-over-Year, But Reduces Next Qtr Guidance
by David Gross
QLogic (QLGC) had a strong quarter, growing its top line 16% from a year ago to $143 million. However it's getting hit in after hours trading as it took revenue guidance down for next quarter from $150 million to a range of $143 million to $147 million. It's not getting beaten as badly as rival Mellanox (MLNX), which fell 32% today after guiding for a 7% sequential revenue decline, but it's down about 11% off this news from the earnings call.
QLogic (QLGC) had a strong quarter, growing its top line 16% from a year ago to $143 million. However it's getting hit in after hours trading as it took revenue guidance down for next quarter from $150 million to a range of $143 million to $147 million. It's not getting beaten as badly as rival Mellanox (MLNX), which fell 32% today after guiding for a 7% sequential revenue decline, but it's down about 11% off this news from the earnings call.
Top-of-Rack (ToR) Switching – Better or Worse for Your Data Center?
by Lisa Huff
Earlier this month I talked about how ToR switching has become popular in the data center and how large switch manufacturers are telling you that it’s really the only way to implement 10G Ethernet. I left that post with this question – “But is it the best possible network architecture for the data center?” And, I promised to get back to you with some assessments.
The answer, of course, is that it depends. Mainly, it depends on what you’re trying to achieve. There are many considerations when moving to this topology. Here are just a few:
2) Cost 2: While the installation of the structured cabling is expensive, if you choose the latest and greatest like CAT6A or CAT7 for copper and OM3 or OM4 for fiber, it typically lasts at least 10 years and could last longer. It can stay there for at least two and possibly three network equipment upgrades. How often do you think you’ll need to replace your ToR switches? Probably every three-to-five years.
3) Cost 3: Something most data center managers haven’t considered – heat. I’ve visited a couple of data centers that have implemented ToR switching only to see that after about a month, some of the ports were seeing very high BER’s to the point where they would fail. What was happening is that the switch is deeper than the servers that are stacked below it and was trapping the exhaust heat at the top of the rack where some “questionable” patch cords were being used. This heat caused out-of-spec insertion loss on these copper patch cords and therefore bit errors.
4) Cost 4: More switch ports than you can actually use within a rack. Some people call this oversubscription. My definition (and the industry’s) for oversubscription is just the opposite so I will not use this term. But, the complaint is this – cabinets are typically 42U or 48U. Each server, if you’re using pizza-box servers, are 1U or 2U. You need a UPS, which is typically 2U or 4U and your ToR switch takes up 1U or 2U. So, the maximum amount of servers you can have in a rack would realistically be 40. Most data centers have much less than this – around 30. In order to connect all of these servers to a ToR switch, you would need a 48-port switch. So you’re paying for eighteen ports that you will most likely never use. Or, what I’ve seen happen sometimes, is that data center managers want to use these extra ports so they connect them to servers in the next cabinet – now you have a cabling nightmare.
So I’ve listed some of the downside. In a future post, I’ll give you some advantages of ToR switching.
Wednesday, July 21, 2010
Mellanox Revenue up 58% year-over year, F5 up 46% UPDATED
Mellanox (MLNX) and F5 (FFIV), both dependent on data centers and HPC both reported strong revenue growth today, with Mellanox's top line up 10% sequentially and 58% year-over-year, and F5 up 12% sequential and 46% y/y. But the similarities end there. Mellanox guided for a 7% revenue decline next quarter due to product mix, while F5 guided up, 5% past current estimates. After hours trading reflected these two very different outlooks for the upcoming quarter.
Mellanox blamed a shift in product mix from boards to chips, as it ramps up volumes of its silicon for LAN-on-Motherboard cards, which sell for far less than its InfiniBand HCAs. Still, InfiniBand's share of Top500 Supercomputing interconnects is rising, from 30% in June 2009 to 36% in November 2009 to 42% in June 2010. If this business is all going to QLogic (QLGC), we'll find out tomorrow, when that supplier reports.
Mellanox blamed a shift in product mix from boards to chips, as it ramps up volumes of its silicon for LAN-on-Motherboard cards, which sell for far less than its InfiniBand HCAs. Still, InfiniBand's share of Top500 Supercomputing interconnects is rising, from 30% in June 2009 to 36% in November 2009 to 42% in June 2010. If this business is all going to QLogic (QLGC), we'll find out tomorrow, when that supplier reports.
Common Electrical Interface for 25/28G - Possibility or Pipe Dream?
by Lisa Huff
Monday, I sat through a workshop hosted by the Optical Interconnecting Forum (OIF) on its “Common Electrical Interface (CEI) project for 28G Very Short Reach (VSR).” What quickly became clear to me was that I was in a room of VERY optimistic engineers.
I sat through presentations that were characterized as “Needs of the Industry,” which consisted of content from the leaders of IEEE 802.3ba (40/100G Ethernet), T11.2 (Fibre Channel) and InfiniBand standards groups. Yet all of these representatives made sure they carefully stated that what they were presenting was their own opinions and not that of their standards groups, which I found odd since most of what they showed was directly from the standards. Legalities I guess. I also noticed that they never really sited any kind of independent market research or analysis of what the “needs of the industry” were. For instance, one speaker said that InfiniBand has a need for 26AWG, 3-meter copper cable assemblies for 4x25G operation in order to keep the cost down within a cabinet. Yet, he did not present any data or even mention what customers are asking for this. Maybe this exists, but to me unless it is presented, the case for it is weak. I do have evidence directly from some clustering folks that they are moving away from copper in favor of fiber for many reasons – lower power consumption, weight of cabling, higher density, and room in cabinets, pathways and spaces.
Today, data center managers are really still just starting to realize the benefits of deploying 10G, which has yet to reach its market potential. I understand that standards groups must work on future data rates ahead of broad market demands, but this seems extremely premature. None of the current implementations for 40/100G that use 10G electrical signaling have even been deployed yet (except for maybe a few InfiniBand ones). And, from what I understand from at least one chip manufacturer who sells a lot of 10G repeaters to OEMs for their backplanes, it is difficult enough to push 10G across a backplane or PCB. Why wouldn’t the backplane and PCB experts solve this issue that is here today before they move onto trying to solve a “problem” that doesn’t even exist yet?
Maybe they need to revisit optical backplanes for 25G? It seems to me that 25G really won't be needed any time soon and that their time would be better spent on developing something that would appear to have relevancy beyond 25G. To me, designing some exotic DSP chip that would allow 25G signals to be transmitted over four-to-12 inches of PCB and maybe 3m of copper cable for one generation of equipment may not be very productive. Maybe this is simpler than I anticipate, but then again, there was a similar but a little more complicated problem with 10GBASE-T and look how that turned out...
Tuesday, July 20, 2010
40/100G – A Major Shift to Parallel Optics?
by Lisa Huff
Parallel-optics have been around for more than a decade – remember SNAP12 and POP4? These were small 12 and four-fiber parallel-optics modules that were developed for telecom VSR applications. They never really caught on for Ethernet networks though. Other than a few CWDM solutions, volume applications for datacom transceivers have been serial short-wavelength ones. At 40G, this is changing.High performance computing (HPC) centers have already adopted parallel optics at 40 and 120G using InfiniBand (IB) 4x and 12x DDR. And, they are continuing this trend through their next data rate upgrades – 80 and 240G. While in the past I thought of HPC as a small, somewhat niche market, I now think this is shifting due to two major trends:
- IB technology has crossed over into 40 and 100-Gigabit Ethernet in the form of both active optical cable assemblies, CFP and CXP modules.
- More and more medium-to-large enterprise data centers are starting to look like HPC clusters with masses of parallel processing
Once parallel-optics based transceivers are deployed for 40/100G networks, will we ever return to serial transmission?
Monday, July 19, 2010
Updated July-August Earnings Calendar
Earnings season starts today for data center stocks, here's the latest calendar...
IBM July 19
IBM July 19
VMW July 20
ALTR July 20
APH July 21
ALTR July 20
APH July 21
EMC July 21
FFIV July 21
XLNX July 21
XLNX July 21
MLNX July 22
QLGC July 22
QLGC July 22
RVBD July 22
DLR July 23
SVVS July 26 10am
LVLT July 27 10am
BRCM July 27
RDWR July 27
RDWR July 27
VOLT July 28 10am
AKAM July 28
EQIX July 28
LSI July 28
NETL July 28
BDC July 29
EXTR Aug 2
LSI July 28
NETL July 28
BDC July 29
EXTR Aug 2
RAX Aug 2
EMR Aug 3
EMR Aug 3
DFT Aug 4 (release on Aug 3)
INAP Aug 4
TMRK Aug 4
CRAY Aug 4
CRAY Aug 4
LLNW Aug 5
ELX Aug 5
SGI Aug 6
ELX Aug 5
SGI Aug 6
CSCO Aug 11
DELL Aug 19
HPQ Aug 19
BCSI Aug 20
HPQ Aug 19
BCSI Aug 20
Friday, July 16, 2010
Network Utilization Has Nothing to do with Upgrading Bandwidth
by David Gross
One of the questions I've been asked by hedge funds is whether networks are full enough to justify upgrades to 40 or 100 gigabit, as if communications networks are like airplanes or railcars, and only need to be expanded if they're already full. But this misses the point of why upgrades beyond 10 gigabit are needed, especially in the data center, where it's long been possible to provision 10 gigabit links for much less cost than longer reach 1 gigabit connections in telecom networks.
Financial professionals more than anyone should understand the upgrade past 10 gigabit is primarily about latency, not bandwidth. And one of the primary contributors to latency, serialization delay, drops proportionally to increases in line rate. A 1500 byte packet, for example, has a 1.2 microsecond delay at 10 Gbps, but a .3 microsecond, or 300 nanosecond, delay at 40 Gbps. With financial services, one of the leading buyers of high capacity switches, the upgrade is therefore cost justified by the value of reducing execution times by 900 nanoseconds, which is far more than the cost of a new switch for many firms. None of this has anything to do with whether the existing network peaks at 10% utilization during the day, or at 60%.
Even in longer-reach networks, upgrades are tied to revenue, not just network utilization. When AT&T (T) upgraded its MPLS core to 40G, it included nine out-of-region markets where it did not offer U-Verse or any video service. The financial justification was to maintain low latency for commercial customers whose traffic was riding that MPLS networks, many of whom spend tens of thousands a month with the carrier.
Bandwidth is often described as a faster link or fatter pipe, the latter might make sense when talking about consumer video, but no one's getting 40 or 100 gigabits to their home anytime soon. In data centers and even long-reach corporate networks, it makes more sense to think of upgrades in terms of raw speed, because a faster path, not a wider lane, is essential when you're trying to make a quick trade.
One of the questions I've been asked by hedge funds is whether networks are full enough to justify upgrades to 40 or 100 gigabit, as if communications networks are like airplanes or railcars, and only need to be expanded if they're already full. But this misses the point of why upgrades beyond 10 gigabit are needed, especially in the data center, where it's long been possible to provision 10 gigabit links for much less cost than longer reach 1 gigabit connections in telecom networks.
Financial professionals more than anyone should understand the upgrade past 10 gigabit is primarily about latency, not bandwidth. And one of the primary contributors to latency, serialization delay, drops proportionally to increases in line rate. A 1500 byte packet, for example, has a 1.2 microsecond delay at 10 Gbps, but a .3 microsecond, or 300 nanosecond, delay at 40 Gbps. With financial services, one of the leading buyers of high capacity switches, the upgrade is therefore cost justified by the value of reducing execution times by 900 nanoseconds, which is far more than the cost of a new switch for many firms. None of this has anything to do with whether the existing network peaks at 10% utilization during the day, or at 60%.
Even in longer-reach networks, upgrades are tied to revenue, not just network utilization. When AT&T (T) upgraded its MPLS core to 40G, it included nine out-of-region markets where it did not offer U-Verse or any video service. The financial justification was to maintain low latency for commercial customers whose traffic was riding that MPLS networks, many of whom spend tens of thousands a month with the carrier.
Bandwidth is often described as a faster link or fatter pipe, the latter might make sense when talking about consumer video, but no one's getting 40 or 100 gigabits to their home anytime soon. In data centers and even long-reach corporate networks, it makes more sense to think of upgrades in terms of raw speed, because a faster path, not a wider lane, is essential when you're trying to make a quick trade.
Thursday, July 15, 2010
Is Data Center Structured Cabling Becoming Obsolete?
by Lisa Huff
Today if you walk into a “typical” data center you’ll see tons of copper Category cabling in racks, under the raised floor and above cabinets. Of course, it can be argued that there is no such thing as a “typical” data center. But, regardless, most of them still have a majority of copper cabling – but that’s starting to change. Over the last year, we’ve seen the percentage of copper cabling decrease from about 90-percent to approximately 80-percent and according to several data center managers I’ve spoken to lately, they would go entirely fiber if they could afford to.
Well, at 10G, they may just get their wish. Not on direct cost, but perhaps on operating or indirect costs. While copper transceivers at Gigabit data rates cost less than $5 per port (for the switch manufacturer), short wavelength optical ones still hover around $20/port (for the switch manufacturer) and about $120/port for the end user – a massive markup we’ll explore later. But 10GBASE-T ports are nearly non-existent – for many reasons, but the overwhelming one is power consumption. 10GBASE-SR ports with SFP+ modules are now available that consume less than 1W of power, while 10G copper chips are struggling to meet a less than 4W requirement. Considering the fact that power and cooling densitie4s are increasingly issues for data center managers, this alone may steer them to fiber.
This has also led to interconnect companies like Amphenol (APH), Molex (MOLX) and Tyco Electronics (TEL) to take advantage of their short-reach copper twinax technology in the form of the SFP+ direct attach cable assemblies and a change in network topology – away from structured cabling. So while structured cabling may be a cleaner and more flexible architecture, many have turned to top-of-rack switching and direct-connect cabling just so they can actually implement 10-Gigabit Ethernet. Of course, Brocade (BRCD), Cisco (CSCO), Force10 and others support this change because they sell more equipment. But is it the best possible network architecture for the data center?
Wednesday, July 14, 2010
How Rackspace Saved the Managed Hosting Industry
by David Gross
Since the USinternetworking bankruptcy in 2001, there has been a lot of skepticism about the managed hosting business. It squeezes in between the more asset heavy collocation industry, and the more people heavy Software-as-a-Service industry. This requires that managed hosters walk a financial tightrope between wrecking the balance sheet with too many fixed asset purchases, or destroying the income statement by hiring too many people.
Before the USinternetworking story ended at chapter 11, there were clear warning signs of trouble with the company that were evident in its asset utilization and employee productivity ratios. It had a .48 Revenue/PP&E ratio, and just $95,000 of revenue per employee. Essentially, it was trying to be capital-intensive and labor-intensive at the same time. In addition to the dot com bust, this sent everyone scrambling away from the managed services market, and left it as a side service for collocation providers and telecom carriers, except for one company that decided to focus on it - Rackspace (RAX).
Rackspace has carefully managed both its asset utilization and employee productivity to the point that its EBITDA margins now top 30%, which is remarkable considering how this type of service was once seen as a one-way ticket to bankruptcy court. The company's 1.59 Revenue/PP&E ratio is among the highest outside of the REITs and co-lo providers. Moreover, its revenue per server has been increasing from $7,700 to 2005 to nearly $12,000 today.
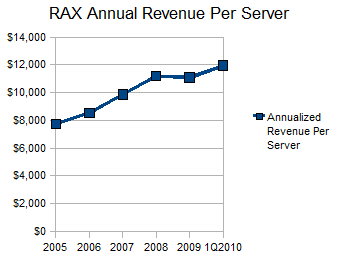
The most important thing the company has done to achieve its high asset utilization has been to stay out of the unmanaged collocation business. Specifically, this has produced three major benefits:
The financial benefits of sticking to managed services for Rackspace have been similar to the financial benefits Equinix (EQIX) has seen from sticking to unmanaged services, and that Digital Realty (DLR) has seen from being a simple REIT. This is best seen in each company's asset and employee utilization ratios, which are vastly different for each.
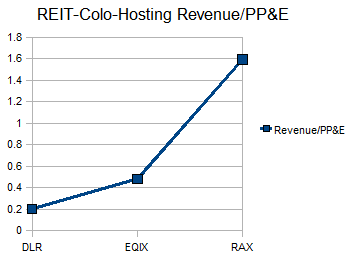
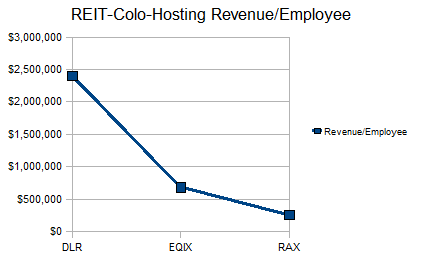
As you can see, the asset and employee utilization numbers for each company differ significantly, which is why these services do not mix well under one corporate entity. Rackspace's cloud service has not resulted in over-diversification for the company, because it runs at similar revenue/employee and revenue/asset ratios to the traditional hosting service, and it allows the company to use idle capacity in existing servers.
In addition to stronger balance sheet and income statement ratios, these focused providers have also seen higher revenue growth over the last year, as other competitors sort out which services they do and do not want to offer. Nonetheless, it does not take deep technical knowledge to succeed in this business, just a simple understanding of how to choose between spending on people or spending on assets.
Since the USinternetworking bankruptcy in 2001, there has been a lot of skepticism about the managed hosting business. It squeezes in between the more asset heavy collocation industry, and the more people heavy Software-as-a-Service industry. This requires that managed hosters walk a financial tightrope between wrecking the balance sheet with too many fixed asset purchases, or destroying the income statement by hiring too many people.
Before the USinternetworking story ended at chapter 11, there were clear warning signs of trouble with the company that were evident in its asset utilization and employee productivity ratios. It had a .48 Revenue/PP&E ratio, and just $95,000 of revenue per employee. Essentially, it was trying to be capital-intensive and labor-intensive at the same time. In addition to the dot com bust, this sent everyone scrambling away from the managed services market, and left it as a side service for collocation providers and telecom carriers, except for one company that decided to focus on it - Rackspace (RAX).
Rackspace has carefully managed both its asset utilization and employee productivity to the point that its EBITDA margins now top 30%, which is remarkable considering how this type of service was once seen as a one-way ticket to bankruptcy court. The company's 1.59 Revenue/PP&E ratio is among the highest outside of the REITs and co-lo providers. Moreover, its revenue per server has been increasing from $7,700 to 2005 to nearly $12,000 today.
The most important thing the company has done to achieve its high asset utilization has been to stay out of the unmanaged collocation business. Specifically, this has produced three major benefits:
- The company has not been forced to build data centers near its customers, it's left the mad scramble for space in Northern New Jersey to the collocation providers, who have to be there for their financial customers
- It has had the resources to expand into cloud hosting, which offers growth opportunities, but significant financial risk for the provider that must both staff up and construct new facilities at the same time
- It has achieved better volume discounts from suppliers, by saving 2/3rds of its capital budget for customer servers and equipment, not new buildings
The financial benefits of sticking to managed services for Rackspace have been similar to the financial benefits Equinix (EQIX) has seen from sticking to unmanaged services, and that Digital Realty (DLR) has seen from being a simple REIT. This is best seen in each company's asset and employee utilization ratios, which are vastly different for each.
As you can see, the asset and employee utilization numbers for each company differ significantly, which is why these services do not mix well under one corporate entity. Rackspace's cloud service has not resulted in over-diversification for the company, because it runs at similar revenue/employee and revenue/asset ratios to the traditional hosting service, and it allows the company to use idle capacity in existing servers.
In addition to stronger balance sheet and income statement ratios, these focused providers have also seen higher revenue growth over the last year, as other competitors sort out which services they do and do not want to offer. Nonetheless, it does not take deep technical knowledge to succeed in this business, just a simple understanding of how to choose between spending on people or spending on assets.
Tuesday, July 13, 2010
Why TCO Models Fail
by David Gross
For years, data center and telecom suppliers have presented TCO models to customers promising a full range of financial benefits, from lower operating costs to more revenue to reduced capex. But they're not taken very seriously. Understanding that these payback scenarios are often created by engineers with limited financial knowledge, some companies will venture out to a large consulting firm that itself has limited product knowledge in order to validate some of their claims. But the result is the same, a McKinsey or Bain mark on a spreadsheet does little to add credibility to numbers that no financial analyst with budget responsibility can take seriously.
The reason these business cases fail include:
In addition to ignoring these financial realities, many business cases get tossed in the trash because they show no understanding of operational realities. This often occurs with the clever models put together by MBA consulting firms with little industry experience. I once saw a business case that showed new revenue amazingly appearing with the purchase of a new switch. What was not shown was any recognition of time needed to sell the 150 gigabit+ capacity within the switch, to negotiate large bandwidth purchases, network planning, circuit ordering, credit checks, or any of the typical issues that come up with major network capacity issues. Adding in reasonable operating expectations for filling capacity threw the IRR under many companies' cost of capital, and made buying the switch a bad deal – per the supplier's own business case.
Having survived two bruising recessions in the last decade, purchasing managers will not go to bat for a vendor that cannot show the financial depth that the finance department needs, or operational understanding that puts credibility behind any financial projections. With so many cost-of-ownership and payback models ending up as a big waste of time and effort, smart hardware suppliers need to reconsider how they present the financial justification for buying their equipment.
For years, data center and telecom suppliers have presented TCO models to customers promising a full range of financial benefits, from lower operating costs to more revenue to reduced capex. But they're not taken very seriously. Understanding that these payback scenarios are often created by engineers with limited financial knowledge, some companies will venture out to a large consulting firm that itself has limited product knowledge in order to validate some of their claims. But the result is the same, a McKinsey or Bain mark on a spreadsheet does little to add credibility to numbers that no financial analyst with budget responsibility can take seriously.
The reason these business cases fail include:
- Scattered Financial Benefits – most financially worthwhile products cut capex, increase productivity, or add to revenue, but not all three
- Automatic Layoffs at Installation – operations staff are often modeled to disappear after a new router or switch is installed, this of course never happens in practice, a more sensible way to present this is to demonstrate that your product can improve productivity, not that it cuts opex
- No Time Value of Money - many engineers and product managers will say “ROI” 100 times without ever showing an IRR, or Internal Rate of Return, on the capital outlay of buying their product. A 15% “ROI” is pretty good if it occurs over 8 months and will beat just about any buyer's cost of capital, but it is dreadful if it occurs over 3 years - the IRR at 8 months is about 23%, while at 3 years it's about 4%.
In addition to ignoring these financial realities, many business cases get tossed in the trash because they show no understanding of operational realities. This often occurs with the clever models put together by MBA consulting firms with little industry experience. I once saw a business case that showed new revenue amazingly appearing with the purchase of a new switch. What was not shown was any recognition of time needed to sell the 150 gigabit+ capacity within the switch, to negotiate large bandwidth purchases, network planning, circuit ordering, credit checks, or any of the typical issues that come up with major network capacity issues. Adding in reasonable operating expectations for filling capacity threw the IRR under many companies' cost of capital, and made buying the switch a bad deal – per the supplier's own business case.
Having survived two bruising recessions in the last decade, purchasing managers will not go to bat for a vendor that cannot show the financial depth that the finance department needs, or operational understanding that puts credibility behind any financial projections. With so many cost-of-ownership and payback models ending up as a big waste of time and effort, smart hardware suppliers need to reconsider how they present the financial justification for buying their equipment.
Monday, July 12, 2010
Luxtera’s Contribution to All-Optical Networks
by Lisa Huff
Last week I wrote about Avago’s new miniaturized transmitters and receivers so today I’d like to introduce you to a similar product from privately-held Luxtera. Well known for its CMOS photonics technology, Luxtera actually introduced its OptoPHY transceivers first – in late 2009.
Luxtera took a different approach to its new high-density, optical interconnect solution. It is a transceiver module and is based on LW (1490nm) optics. Just like Avago’s devices, the transceivers use 12-fiber ribbon cables provided by Luxtera, but that’s really were the similarities end. The entire 10G–per-lane module only uses about 800mW compared to Avago's 3W, and they are true transceivers as opposed to separate transmitters and receivers. Luxtera is shipping its device to customers, but have not announced which ones yet.
In addition to the projected low cost for these devices, what should also be noted is that all of the solutions mentioned in the last three entries – Intel’s Light Peak; Avago’s MicroPOD and Luxtera’s OptoPHY – have moved away from the pluggable module product theme to board-mounted devices. This in and of itself may not seem significant until you think about why there were pluggable products to begin with. The original intent was to give OEMs and end users flexibility in design so they could use an electrical, SW optical or LW optical device in a port depending on what length of cable needed to be supported. You could also grow as you needed to – so only populate those ports required at the time of installation and add others when necessary. The need for this flexibility has seemed to have waned in recent years in favor of density, lower cost and lower power consumption. The majority of pluggable ports are now optical ones, so why not just move back to board-mounted products that can achieve the miniaturization, price points and lower power consumption?
Last week I wrote about Avago’s new miniaturized transmitters and receivers so today I’d like to introduce you to a similar product from privately-held Luxtera. Well known for its CMOS photonics technology, Luxtera actually introduced its OptoPHY transceivers first – in late 2009.
Luxtera took a different approach to its new high-density, optical interconnect solution. It is a transceiver module and is based on LW (1490nm) optics. Just like Avago’s devices, the transceivers use 12-fiber ribbon cables provided by Luxtera, but that’s really were the similarities end. The entire 10G–per-lane module only uses about 800mW compared to Avago's 3W, and they are true transceivers as opposed to separate transmitters and receivers. Luxtera is shipping its device to customers, but have not announced which ones yet.
In addition to the projected low cost for these devices, what should also be noted is that all of the solutions mentioned in the last three entries – Intel’s Light Peak; Avago’s MicroPOD and Luxtera’s OptoPHY – have moved away from the pluggable module product theme to board-mounted devices. This in and of itself may not seem significant until you think about why there were pluggable products to begin with. The original intent was to give OEMs and end users flexibility in design so they could use an electrical, SW optical or LW optical device in a port depending on what length of cable needed to be supported. You could also grow as you needed to – so only populate those ports required at the time of installation and add others when necessary. The need for this flexibility has seemed to have waned in recent years in favor of density, lower cost and lower power consumption. The majority of pluggable ports are now optical ones, so why not just move back to board-mounted products that can achieve the miniaturization, price points and lower power consumption?
Friday, July 9, 2010
Fibre Channel over Ethernet - Reducing Complexity or Adding Cost?
by David Gross
Data center servers typically have two or three network cards. Each of these adapters attaches to a different network element—one which supports storage over Fibre Channel, a second for Ethernet networking, and a third card for clustering, which typically runs over InfiniBand. At first glance, this mix of networks looks messy and duplicative, and has led to calls for a single platform that can address all of these applications on one adapter.
Five years ago, when the trend was "IP on everything", iSCSI was seen as the one protocol that could pull everything together. Today, with the trend being "Everything over Ethernet", Fibre Channel over Ethernet, or FCoE, is now hailed as the way to put multiple applications on one network. However, there is still growing momentum behind stand-alone InfiniBand and Ethernet, with little indication that the market is about to turn to a single grand network that does everything.
Stand-Alone Networks Still Growing
In spite of all the theoretical benefits of a single, "converged" network, InfiniBand, which is still thought by many to be an odd, outlier of a protocol, continues to grow within its niche. According to Top 500.org, the number of InfiniBand-connected CPU cores in large supercomputers grew 70% percent from June 2009 to June 2010, from 1.08 million to 1.8 million. QLogic (QLGC) and Voltaire (VOLT) recently announced major InfiniBand switch deployments at the University of Edinburgh and Tokyo Institute of Technology respectively, while Mellanox (MLNX) recently publicized a Google (GOOG) initiative that's looking at InfiniBand as a low power way of expanding data center networks.
InfiniBand remains financially competitive because of its switch port costs. With 40 gigabit InfiniBand ports available for $400, there is a growing, not declining, incentive to deploy them.
In addition to low prices for single protocol switch ports, another challenge facing the "converged" network is low prices for single protocol server cards. While having multiple adapters on each server might seem wasteful, 10 Gigabit Ethernet server NICs have come down in price dramatically over the last few years, with street pricing on short-reach fiber cards dropping under $500, and prices on copper CX4 adapters falling under $400. Fibre Channel over Ethernet Converged Network Adapters, meanwhile, still cost over $1,500. The diverged network architecture, while looking terrible in vendor PowerPoints, can actually look very good in capital budgets.
Data Centers are Not Labor-Intensive
In addition to capital cost considerations, many of the operational savings from combining Local Area Networks and Storage Area Networks can be difficult to achieve, because most data centers are already running at exceptionally high productivity levels. Stand-alone data centers, like those Yahoo (YHOO) and Microsoft (MSFT) are currently building in upstate New York and Iowa, cost nearly $1,000 per square foot to construct - more than a Manhattan office tower. Additionally, they employ about one operations worker for every 2,000 square feet of space, ten times less than a traditional office where each worker has about 200 square feet. This also means the data center owners are spending about $2 million in capital for every person employed at the facility.
Among publicly traded hosting providers, many are reporting significant revenue growth without having to staff up significantly. Rackspace (RAX), for example, saw revenue increase by 18% in 2009, when it reported $629 million in sales. But it only increased its work force of “Rackers”, as the company calls its employees, by 6%. At the same time, capex remained very high at $185 million, or a lofty 29% of revenue. In the data center, labor costs are being dramatically overshadowed by capital outlays, making the potential operational savings of LAN/SAN integration a nice benefit, but not as pressing a financial requirement as improving IRRs on capital investments.
FCoE does not look like a complete bust, there are likely to be areas where it makes sense because of its flexibility, such as servers on the edge of the SAN. A lot of work has gone into making sure FCoE fits in well with existing networks, but much more effort is needed to make sure it fits in well with capital budgets.
Chief Technology Analyst Lisa Huff contributed to this article
Data center servers typically have two or three network cards. Each of these adapters attaches to a different network element—one which supports storage over Fibre Channel, a second for Ethernet networking, and a third card for clustering, which typically runs over InfiniBand. At first glance, this mix of networks looks messy and duplicative, and has led to calls for a single platform that can address all of these applications on one adapter.
Five years ago, when the trend was "IP on everything", iSCSI was seen as the one protocol that could pull everything together. Today, with the trend being "Everything over Ethernet", Fibre Channel over Ethernet, or FCoE, is now hailed as the way to put multiple applications on one network. However, there is still growing momentum behind stand-alone InfiniBand and Ethernet, with little indication that the market is about to turn to a single grand network that does everything.
Stand-Alone Networks Still Growing
In spite of all the theoretical benefits of a single, "converged" network, InfiniBand, which is still thought by many to be an odd, outlier of a protocol, continues to grow within its niche. According to Top 500.org, the number of InfiniBand-connected CPU cores in large supercomputers grew 70% percent from June 2009 to June 2010, from 1.08 million to 1.8 million. QLogic (QLGC) and Voltaire (VOLT) recently announced major InfiniBand switch deployments at the University of Edinburgh and Tokyo Institute of Technology respectively, while Mellanox (MLNX) recently publicized a Google (GOOG) initiative that's looking at InfiniBand as a low power way of expanding data center networks.
InfiniBand remains financially competitive because of its switch port costs. With 40 gigabit InfiniBand ports available for $400, there is a growing, not declining, incentive to deploy them.
In addition to low prices for single protocol switch ports, another challenge facing the "converged" network is low prices for single protocol server cards. While having multiple adapters on each server might seem wasteful, 10 Gigabit Ethernet server NICs have come down in price dramatically over the last few years, with street pricing on short-reach fiber cards dropping under $500, and prices on copper CX4 adapters falling under $400. Fibre Channel over Ethernet Converged Network Adapters, meanwhile, still cost over $1,500. The diverged network architecture, while looking terrible in vendor PowerPoints, can actually look very good in capital budgets.
Data Centers are Not Labor-Intensive
In addition to capital cost considerations, many of the operational savings from combining Local Area Networks and Storage Area Networks can be difficult to achieve, because most data centers are already running at exceptionally high productivity levels. Stand-alone data centers, like those Yahoo (YHOO) and Microsoft (MSFT) are currently building in upstate New York and Iowa, cost nearly $1,000 per square foot to construct - more than a Manhattan office tower. Additionally, they employ about one operations worker for every 2,000 square feet of space, ten times less than a traditional office where each worker has about 200 square feet. This also means the data center owners are spending about $2 million in capital for every person employed at the facility.
Among publicly traded hosting providers, many are reporting significant revenue growth without having to staff up significantly. Rackspace (RAX), for example, saw revenue increase by 18% in 2009, when it reported $629 million in sales. But it only increased its work force of “Rackers”, as the company calls its employees, by 6%. At the same time, capex remained very high at $185 million, or a lofty 29% of revenue. In the data center, labor costs are being dramatically overshadowed by capital outlays, making the potential operational savings of LAN/SAN integration a nice benefit, but not as pressing a financial requirement as improving IRRs on capital investments.
FCoE does not look like a complete bust, there are likely to be areas where it makes sense because of its flexibility, such as servers on the edge of the SAN. A lot of work has gone into making sure FCoE fits in well with existing networks, but much more effort is needed to make sure it fits in well with capital budgets.
Chief Technology Analyst Lisa Huff contributed to this article
Thursday, July 8, 2010
Optical Interconnects Could Lead to All-Optical Data Center Switches
By Lisa Huff
On-board interconnects have for some time just been handled with copper traces, but with data rates now reaching beyond 10G, this is ripe for change. In fact, it is already changing; evidenced by the big splash IBM and Avago Technologies made at this year's OFC/NFOEC conference. The computer giant and transceiver manufacturer teamed to develop what they are calling "the fastest, most energy-efficient embedded interconnect technology of its kind."
Deemed the MicroPOD™, Avago developed it for IBM's next generation supercomputer, POWER7™. While it was designed for HPC server interconnects, it could be used for on-board or chip-to-chip interconnects as well. The devices use a newly designed miniature detachable connector from US CONEC called PRIZM™ LightTurn™. The system has separate transmitter and receiver modules that are connected through a 12-fiber ribbon. Each lane supports up to 12.5 Gbps. It uses 850nm VCSEL and PIN diode arrays. The embedded modules can be used for any board-level or I/O-level application by either using two PRIZM LightTurn connectors or one PRIZM LightTurn and one MPO.
While these modules are currently for the HPC market, Avago designed something very similar for Intel and its Light Peak interconnect system for what some are calling “optical USB.” MicroPOD is targeted at high-density environments so a natural extension of its market reach would be into switches and routers. The market for such devices probably will not become huge in the next few years, but it is exciting to see that companies in this space have started to spend R&D dollars again and that there are at least a few customers willing to employ the technology right out of the gate. Of course, it must be noted that this project was partially funded by DARPA.
But this technology MUST be too expensive for the typical piece of network equipment right? Not so, says Avago, because the manufacturing process is 100-percent automated and with Avago's vertical integration, the prices (at volume) may actually be able to rival those of today's transceivers. I’ll hold judgment until Avago proves it can win more than one big customer, however, I think MicroPOD holds the promise to change the paradigm for on-board, board-to-board and even network-element-to-network-element optical interconnects.
On-board interconnects have for some time just been handled with copper traces, but with data rates now reaching beyond 10G, this is ripe for change. In fact, it is already changing; evidenced by the big splash IBM and Avago Technologies made at this year's OFC/NFOEC conference. The computer giant and transceiver manufacturer teamed to develop what they are calling "the fastest, most energy-efficient embedded interconnect technology of its kind."
Deemed the MicroPOD™, Avago developed it for IBM's next generation supercomputer, POWER7™. While it was designed for HPC server interconnects, it could be used for on-board or chip-to-chip interconnects as well. The devices use a newly designed miniature detachable connector from US CONEC called PRIZM™ LightTurn™. The system has separate transmitter and receiver modules that are connected through a 12-fiber ribbon. Each lane supports up to 12.5 Gbps. It uses 850nm VCSEL and PIN diode arrays. The embedded modules can be used for any board-level or I/O-level application by either using two PRIZM LightTurn connectors or one PRIZM LightTurn and one MPO.
While these modules are currently for the HPC market, Avago designed something very similar for Intel and its Light Peak interconnect system for what some are calling “optical USB.” MicroPOD is targeted at high-density environments so a natural extension of its market reach would be into switches and routers. The market for such devices probably will not become huge in the next few years, but it is exciting to see that companies in this space have started to spend R&D dollars again and that there are at least a few customers willing to employ the technology right out of the gate. Of course, it must be noted that this project was partially funded by DARPA.
But this technology MUST be too expensive for the typical piece of network equipment right? Not so, says Avago, because the manufacturing process is 100-percent automated and with Avago's vertical integration, the prices (at volume) may actually be able to rival those of today's transceivers. I’ll hold judgment until Avago proves it can win more than one big customer, however, I think MicroPOD holds the promise to change the paradigm for on-board, board-to-board and even network-element-to-network-element optical interconnects.
July-August Data Center Stocks Earnings Calendar
More will be coming as they are announced...
IBM July 19
VMW July 20
ALTR July 20
ALTR July 20
EMC July 21
FFIV July 21
QLGC July 22
QLGC July 22
RVBD July 22
DLR July 23
LVLT July 27 10am
AKAM July 28
DFT Aug 4 (release on Aug2)
CSCO Aug 11
DELL Aug 19
HPQ Aug 19
HPQ Aug 19
IBM July 19
Wednesday, July 7, 2010
Intel's Light Peak Optical Interconnect - Coming to Data Centers?
By Lisa Huff
Intel (INTC) made a big splash at its developer's forum in September 2009 by introducing its Light Peak technology. Light Peak uses a new controller chip with LOMF (Laser Optimized Multimode Fiber) and a 10G 850nm VCSEL-based module with a new optical interface connector, which has yet to be determined. It is aimed at replacing all of your external connectors on your PC including USB, IEEE 1394, HDMI, DP, PCIe, etc. It is also targeted at other consumer electronic devices like smart phones and MP3 players.
Intel designed both the controller chip and the optical module, but will only supply the chip. It is working with a couple of top optical component manufacturers on the modules—Avago (AVGO) and TDK. The semiconductor giant expects to ship its first products this year, but would not say who its initial customers will be. It did tell me that it has "received general support from the PC makers" and both SONY and Nokia have gone on record publicly supporting Light Peak. Both companies are willing to entertain a new standard centered on the Light Peak technology. These labors are expected to pay off with formal standardization starting this year.
According to Intel, Light Peak is expected to start shipping this year with several PC manufacturers evaluating it. Next year is anticipated to be a transitional year and by 2012, we should start seeing Light Peak commercially available on PCs. While I would never bet against Intel, this is quite an aggressive schedule. Even USB took longer than that to be adopted and it was a copper solution that was easily implemented by consumers. However, it sure would be nice to have just one connector for my PC!
While Intel says it has targeted this technology at consumers, with its 10G data rate and 100-meter optical reach, it could easily be extended to LAN and/or data center applications.
Intel (INTC) made a big splash at its developer's forum in September 2009 by introducing its Light Peak technology. Light Peak uses a new controller chip with LOMF (Laser Optimized Multimode Fiber) and a 10G 850nm VCSEL-based module with a new optical interface connector, which has yet to be determined. It is aimed at replacing all of your external connectors on your PC including USB, IEEE 1394, HDMI, DP, PCIe, etc. It is also targeted at other consumer electronic devices like smart phones and MP3 players.
Intel designed both the controller chip and the optical module, but will only supply the chip. It is working with a couple of top optical component manufacturers on the modules—Avago (AVGO) and TDK. The semiconductor giant expects to ship its first products this year, but would not say who its initial customers will be. It did tell me that it has "received general support from the PC makers" and both SONY and Nokia have gone on record publicly supporting Light Peak. Both companies are willing to entertain a new standard centered on the Light Peak technology. These labors are expected to pay off with formal standardization starting this year.
According to Intel, Light Peak is expected to start shipping this year with several PC manufacturers evaluating it. Next year is anticipated to be a transitional year and by 2012, we should start seeing Light Peak commercially available on PCs. While I would never bet against Intel, this is quite an aggressive schedule. Even USB took longer than that to be adopted and it was a copper solution that was easily implemented by consumers. However, it sure would be nice to have just one connector for my PC!
While Intel says it has targeted this technology at consumers, with its 10G data rate and 100-meter optical reach, it could easily be extended to LAN and/or data center applications.
Tuesday, July 6, 2010
Equinix, F5, and Akamai - Growing More by Doing Less
by David Gross
I wrote last week that data center revenue continues to grow in spite of the economy. In particular, three companies from different segments of the data center market, Equinix (EQIX), F5 (FFIV), and Akamai (AKAM), have increased their top line over the last 12 months. However, in years past, I remember hearing how they were going to go away.
Equinix has grown 24% year-over-year as its data centers continue to fill up, and its lease rates continue to rise. But I remember in 2000 hearing how Equinix was not going to stick around a long time, because hosting leaders like Exodus, in addition to the telcos, would put it out of business, and that its service line was too thin. Ten years later, Exodus and many of the ISPs who were supposed to put Equinix out of business are now out of business themselves.
The benefits of a tight product focus have extended to the network equipment market, where Cisco (CSCO) did not have a strong presence in layer 4-7 switching market until it bought Arrowpoint at the top of the market in 2000. And I remember in 2000, the load balancer everyone raved about was not Arrowpoint's, or even F5's BIG-IP , but Foundry's ServerIron. The challenge for the ServerIron was not performance, customer acceptance, or market share, but its parent company's focus on the much larger Ethernet switch market. Today, F5 has twice the market cap of the merged Brocade (BRCD) and Foundry company.
As with F5, economic conditions did not prevent Akamai from reporting year-over-year growth of 12% last quarter. But the last recession did not go too well for the content distribution network provider. It lost its founder in the 9/11 attacks. In 2002, its revenue declined, and it posted an operating margin of minus 141%, which led Wall Street to classify it as another low margin telecom transport provider. The consensus thinking was the CDN market was too small to be important, and if it ever got big, a large carrier would come in and take it over. Yet as it recovered in the mid-2000s, Akamai wisely avoided any temptation to over-diversify. Eight years since bottoming out, the company has grown its top line sixfold, and is on the verge of crossing $1 billion in sales. However, much of its financial strength is not reflected in its income statement, but its balance sheet, where unlike virtually every telco, it has very little long-term debt.
Akamai's primary telco competitor is Level 3 (LVLT), which got into the CDN market by buying Savvis' (SVVS) old business, which got into the CDN market itself by acquiring the American assets of my former employer, Cable & Wireless, which got into CDNs by acquiring Digital Island. Level 3 has had some big wins recently, including mlb.com, but in addition to having to support a wide range of telecom services, it is weighed down by a significant debt load.
It is very easy to cave in to Wall Street pressure to boost top line numbers by making questionable R&D choices, or by entering a market where there is little chance of ever being the number one or two supplier. This pressure is often greatest when multiples are high, and executives start scrambling to justify a growing market cap. But by refusing to go on wild revenue chases when times were good, these three companies have increased sales when times have been bad.
I wrote last week that data center revenue continues to grow in spite of the economy. In particular, three companies from different segments of the data center market, Equinix (EQIX), F5 (FFIV), and Akamai (AKAM), have increased their top line over the last 12 months. However, in years past, I remember hearing how they were going to go away.
Equinix has grown 24% year-over-year as its data centers continue to fill up, and its lease rates continue to rise. But I remember in 2000 hearing how Equinix was not going to stick around a long time, because hosting leaders like Exodus, in addition to the telcos, would put it out of business, and that its service line was too thin. Ten years later, Exodus and many of the ISPs who were supposed to put Equinix out of business are now out of business themselves.
The benefits of a tight product focus have extended to the network equipment market, where Cisco (CSCO) did not have a strong presence in layer 4-7 switching market until it bought Arrowpoint at the top of the market in 2000. And I remember in 2000, the load balancer everyone raved about was not Arrowpoint's, or even F5's BIG-IP , but Foundry's ServerIron. The challenge for the ServerIron was not performance, customer acceptance, or market share, but its parent company's focus on the much larger Ethernet switch market. Today, F5 has twice the market cap of the merged Brocade (BRCD) and Foundry company.
As with F5, economic conditions did not prevent Akamai from reporting year-over-year growth of 12% last quarter. But the last recession did not go too well for the content distribution network provider. It lost its founder in the 9/11 attacks. In 2002, its revenue declined, and it posted an operating margin of minus 141%, which led Wall Street to classify it as another low margin telecom transport provider. The consensus thinking was the CDN market was too small to be important, and if it ever got big, a large carrier would come in and take it over. Yet as it recovered in the mid-2000s, Akamai wisely avoided any temptation to over-diversify. Eight years since bottoming out, the company has grown its top line sixfold, and is on the verge of crossing $1 billion in sales. However, much of its financial strength is not reflected in its income statement, but its balance sheet, where unlike virtually every telco, it has very little long-term debt.
Akamai's primary telco competitor is Level 3 (LVLT), which got into the CDN market by buying Savvis' (SVVS) old business, which got into the CDN market itself by acquiring the American assets of my former employer, Cable & Wireless, which got into CDNs by acquiring Digital Island. Level 3 has had some big wins recently, including mlb.com, but in addition to having to support a wide range of telecom services, it is weighed down by a significant debt load.
It is very easy to cave in to Wall Street pressure to boost top line numbers by making questionable R&D choices, or by entering a market where there is little chance of ever being the number one or two supplier. This pressure is often greatest when multiples are high, and executives start scrambling to justify a growing market cap. But by refusing to go on wild revenue chases when times were good, these three companies have increased sales when times have been bad.
Monday, July 5, 2010
ICO, not TCO
One of the most overused sales metrics in technology is “TCO”, or total cost of ownership. For decades now, sales teams have been abusing financial principles in order to get their business customers to buy hardware or software products using this made up metric. There are countless TCO models flying around Silicon Valley, and their ability to move products has more to do with sales skill than financial reality.
But in investigating products that have lasted far longer than the hype accompanying their release, one thing I've found consistently is that they don't have a low TCO, but a low incremental cost of ownership, or what I'll just call ICO, because like Washington, Silicon Valley likes three letter acronyms.
So what is ICO exactly?
Now calculating TCO often involves beating up Excel, plugging data points into macros, and ensuring that in the process, spreadsheet inputs lose all connection to operating reality. Incremental cost of ownership is a highly technical calculation that looks something like this:
Total amount of money needed to purchase product + 0 = Incremental Cost of Ownership
In looking at products and protocols that have been successful over the years, one thing stands out. Not their TCO, but their ICO. From Cisco's 6500 series switches to Gigabit Ethernet, it is hard to find a widely deployed technology that does not have a reasonable incremental cost of ownership. It's important to note that this does not mean the products sell for low margins, Cisco's gross margins have been in the 60s and its net margins in the teens for years, it's hardly scraping by. The same is true for many of its competitors and suppliers. But in spite of all its industry strength, Cisco could do little to save technologies like ATM and RPR, which promised lower TCO though collapsing network layers, but required buying switches with very high incremental costs.
If it weren't for low incremental costs, there would not be much to say about data center networks. The reason linking up is so attractive in data centers instead of through traditional enterprise or carrier networks is because short-reach hardware components are exponentially cheaper. 40 Gig on a sub-20 meter InfiniBand port will only set you back $400, a quarter of the bandwidth on a 10 kilometer metro link will costs about 30 times as much per port. No clever model or PowerPoint will change this.
Just as IRR accompanies ROI in most well-thought out business cases, ICO should accompany any TCO presentation. Regardless of overall economic conditions, products that have promised future opex savings have typically lost out to those bringing high returns on invested capital today. By presenting both ICO and TCO, vendors would show customers that they are addressing the financial risks they deploying networking hardware, rather than just relying on promises of future opex savings.
But in investigating products that have lasted far longer than the hype accompanying their release, one thing I've found consistently is that they don't have a low TCO, but a low incremental cost of ownership, or what I'll just call ICO, because like Washington, Silicon Valley likes three letter acronyms.
So what is ICO exactly?
Now calculating TCO often involves beating up Excel, plugging data points into macros, and ensuring that in the process, spreadsheet inputs lose all connection to operating reality. Incremental cost of ownership is a highly technical calculation that looks something like this:
Total amount of money needed to purchase product + 0 = Incremental Cost of Ownership
In looking at products and protocols that have been successful over the years, one thing stands out. Not their TCO, but their ICO. From Cisco's 6500 series switches to Gigabit Ethernet, it is hard to find a widely deployed technology that does not have a reasonable incremental cost of ownership. It's important to note that this does not mean the products sell for low margins, Cisco's gross margins have been in the 60s and its net margins in the teens for years, it's hardly scraping by. The same is true for many of its competitors and suppliers. But in spite of all its industry strength, Cisco could do little to save technologies like ATM and RPR, which promised lower TCO though collapsing network layers, but required buying switches with very high incremental costs.
If it weren't for low incremental costs, there would not be much to say about data center networks. The reason linking up is so attractive in data centers instead of through traditional enterprise or carrier networks is because short-reach hardware components are exponentially cheaper. 40 Gig on a sub-20 meter InfiniBand port will only set you back $400, a quarter of the bandwidth on a 10 kilometer metro link will costs about 30 times as much per port. No clever model or PowerPoint will change this.
Just as IRR accompanies ROI in most well-thought out business cases, ICO should accompany any TCO presentation. Regardless of overall economic conditions, products that have promised future opex savings have typically lost out to those bringing high returns on invested capital today. By presenting both ICO and TCO, vendors would show customers that they are addressing the financial risks they deploying networking hardware, rather than just relying on promises of future opex savings.
Sunday, July 4, 2010
Yahoo's New Upstate NY Data Center Set to Open In September
Yahoo's (YHOO) new data center, located 20 miles north of Buffalo in Lockport, NY, is set to open this fall. The facility is part of Yahoo's save-the-world environmental strategy, which includes cutting its carbon intensity by 40%. And where better to do that in Western New York, which has a cool climate and inexpensive hydro power, not unlike the Pacific Northwest where Yahoo and other large Internet firms have built stand-alone centers. Yahoo claims its newest data center will have a PUE of 1.08.
This Yahoo center reinforces the trend of stand-alones locating near cheap power, while public data centers remain near abundant fiber optics. It's not unlike the trend that emerged 30-35 years ago with corporate office parks, where many of the single tenant facilities were built in suburbs to be near employees, while multi-tenant buildings stayed closer to downtown to be near transit lines, financial exchanges, or government buildings.
One factor sustaining this trend with data centers is continued advancement in WAN Acceleration technologies to haul traffic out of these facilities. WAN Acceleration used to be focused primarily on TCP windows and HTTP, but new services like Internap's (INAP) XIP, have targeted BGP-caused delays as well. In addition to new public services, stand-alone owners like Google (GOOG) have been drawing on advances in managing long-haul bandwidth from research networks like Intenet2 and ESnet.
In addition to benefiting from new cooling and bandwidth management technologies, this facility will be one of the first large stand-alones in upstate New York. With that region having many of the same climate and renewable energy benefits of Washington and Oregon, it could attract similar stand-alone facilities over the next five years, just as the Pacific Northwest has over the last five.
This Yahoo center reinforces the trend of stand-alones locating near cheap power, while public data centers remain near abundant fiber optics. It's not unlike the trend that emerged 30-35 years ago with corporate office parks, where many of the single tenant facilities were built in suburbs to be near employees, while multi-tenant buildings stayed closer to downtown to be near transit lines, financial exchanges, or government buildings.
One factor sustaining this trend with data centers is continued advancement in WAN Acceleration technologies to haul traffic out of these facilities. WAN Acceleration used to be focused primarily on TCP windows and HTTP, but new services like Internap's (INAP) XIP, have targeted BGP-caused delays as well. In addition to new public services, stand-alone owners like Google (GOOG) have been drawing on advances in managing long-haul bandwidth from research networks like Intenet2 and ESnet.
In addition to benefiting from new cooling and bandwidth management technologies, this facility will be one of the first large stand-alones in upstate New York. With that region having many of the same climate and renewable energy benefits of Washington and Oregon, it could attract similar stand-alone facilities over the next five years, just as the Pacific Northwest has over the last five.
Friday, July 2, 2010
An Overlooked Area of Data Center Technology
Yesterday, Lisa discussed the importance of VCSELs in data center networks. One challenge for investors is that the devices sell for 20-30% gross margins, not unlike most other optical components. However, VCSEL drivers, the chips that tell the lasers what to do, can sell for much higher margins.
Manufacturers of the drivers include Analog Devices, Linear Technology, and over-the-counter stock GigOptix, which announced a follow on offering yesterday. These companies all have gross margins above 50%, although micro-cap GigOptix has experienced significant margin and revenue growth rate volatility as it has grown from $3 million in sales in 2007 to $14 million last year. In addition to these public names, privately-held Inphi is designing analog chips just for 40/100 Gigabit networks and data centers.
Overall, analog and mixed-signal semis are an overlooked component of data center technologies, but are necessary with all the short-reach copper and fiber links. As data center networks continue to expand, investors will benefit from finding these niche opportunities, and not always focusing on the well-known REITs and Collocation providers.
Manufacturers of the drivers include Analog Devices, Linear Technology, and over-the-counter stock GigOptix, which announced a follow on offering yesterday. These companies all have gross margins above 50%, although micro-cap GigOptix has experienced significant margin and revenue growth rate volatility as it has grown from $3 million in sales in 2007 to $14 million last year. In addition to these public names, privately-held Inphi is designing analog chips just for 40/100 Gigabit networks and data centers.
Overall, analog and mixed-signal semis are an overlooked component of data center technologies, but are necessary with all the short-reach copper and fiber links. As data center networks continue to expand, investors will benefit from finding these niche opportunities, and not always focusing on the well-known REITs and Collocation providers.
Thursday, July 1, 2010
VCSELs – Reducing Power Consumption in 10 Gigabit Data Center Networks
Many optical technology proponents have argued for many years that fiber is about to take over all of networking. However, time and time again we have seen copper technologies reinvent themselves to serve at least the last 100 meters in LANs. But with the complicated digital signal processing that is needed to enable the 100-meter operation of copper comes a cost – power consumption. And in data center operations, power consumption may be the single most important issue still needing to be solved.
Before the EPA performed their study on data center power consumption and before the creation of the Green Grid, data center managers were worried more about running out of space than out of power. Now, with complicated electronics and better utilization of server processing through virtualization, lowering power consumption has become more imperative.
VCSEL-based short-wavelength fiber optic networks may be the answer. On a port-by-port basis, optical 10GBASE-SR devices consume four times less power than copper 10GBASE-T ones. And when you have thousands of these ports within your data center, the total power consumption adds up quickly. In future posts, we'll have more quantitative analyses of copper versus fiber decisions for data center networks.
Finisar (FNSR) is the leading manufacturer of VCSELs, and they sell the short range lasers to LAN and SAN suppliers including Brocade (BRCD), QLogic (QLGC), HP (HPQ), and EMC (EMC). While the devices generally sell at low margins, they are an essential part of keeping costs down and power consumption low in data center networks.
submitted by Contributing Analyst Lisa Huff
Before the EPA performed their study on data center power consumption and before the creation of the Green Grid, data center managers were worried more about running out of space than out of power. Now, with complicated electronics and better utilization of server processing through virtualization, lowering power consumption has become more imperative.
VCSEL-based short-wavelength fiber optic networks may be the answer. On a port-by-port basis, optical 10GBASE-SR devices consume four times less power than copper 10GBASE-T ones. And when you have thousands of these ports within your data center, the total power consumption adds up quickly. In future posts, we'll have more quantitative analyses of copper versus fiber decisions for data center networks.
Finisar (FNSR) is the leading manufacturer of VCSELs, and they sell the short range lasers to LAN and SAN suppliers including Brocade (BRCD), QLogic (QLGC), HP (HPQ), and EMC (EMC). While the devices generally sell at low margins, they are an essential part of keeping costs down and power consumption low in data center networks.
submitted by Contributing Analyst Lisa Huff
Subscribe to:
Posts (Atom)